Hash Tables: The Data Structure Behind Almost Everything
"A hash table is a data structure that maps keys to values for highly efficient lookup." -- Gayle Laakmann McDowell, Cracking the Coding Interview
If you have ever used a Python dict, a JavaScript object, or a HashMap in Java, you have used a hash table. It is one of the most practically important data structures in software engineering — and most developers use it daily without knowing how it actually works.
The Core Idea
Turning Keys into Indices
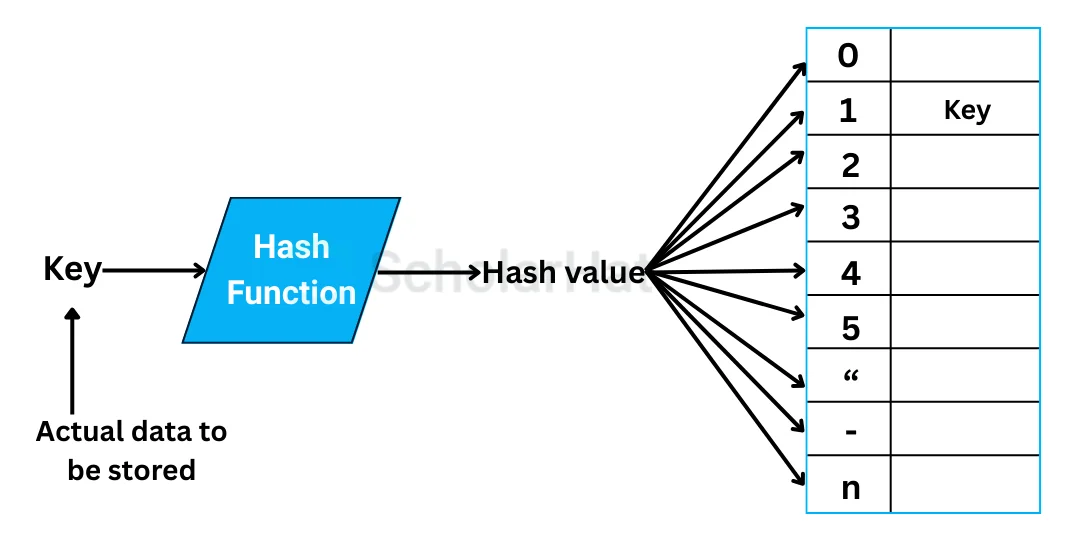
A hash table stores key-value pairs. The trick is getting from a key to the right bucket in O(1) time, on average. It does this in two steps:
- Hash the key: Run the key through a hash function that converts it to an integer.
- Index into an array: Take that integer modulo the array size to get a bucket index.
def get_index(key, table_size):
return hash(key) % table_size
If the hash function distributes keys evenly, each bucket holds a small number of entries and lookups stay fast.
Hash Functions
What Makes a Good One
The hash function is the foundation everything else rests on. A good hash function is:
- Deterministic: The same key always produces the same hash.
- Uniform: Keys spread evenly across the available buckets, minimising clustering.
- Fast: Computing the hash should be cheap.
Python's built-in hash() satisfies all three for its built-in types. This is why dict lookups are O(1) in practice — Python's hash functions are carefully designed to distribute well.
One important detail: only immutable objects are hashable in Python. Lists and dicts cannot be dictionary keys. This is intentional — a mutable key could change after insertion, making the entry unreachable.
Handling Collisions
When Two Keys Hash to the Same Bucket
Collisions — two keys producing the same index — are inevitable. The birthday paradox tells us collisions become likely well before the table is full. There are two main strategies for handling them:
Chaining
Each bucket holds a linked list of all entries that hash to that index. Lookup traverses the list until it finds the matching key.
# Simplified chaining lookup
def get(table, key):
index = hash(key) % len(table)
for stored_key, value in table[index]:
if stored_key == key:
return value
return None
Python's dict uses a variant of this approach.
Open Addressing
Instead of a list per bucket, all entries live in the main array. On collision, the table probes for the next available slot according to a probing sequence (linear, quadratic, or double hashing).
Open addressing has better cache performance because everything lives in one contiguous array, but it requires more careful implementation to handle deletions correctly.
Load Factor and Resizing
The Key to Staying Fast
A hash table's load factor is the ratio of stored entries to total buckets. As the table fills up, collisions increase and performance degrades toward O(n).
The solution is resizing: when the load factor crosses a threshold (typically 0.7 or so), allocate a new larger array and rehash every entry into it.
if len(entries) / len(table) > 0.7:
resize(table) # typically doubles the table size
Resizing is O(n), but it happens infrequently enough that the amortised cost per insertion stays O(1). This is the same trick list.append uses.
Hash Tables vs Red-Black Trees
O(1) vs O(log n)
Both structures support insert, delete, and lookup. The difference is in what they optimise:
- Hash tables: O(1) average for all three operations. No ordering of keys. Performance depends on hash function quality.
- Red-black trees: O(log n) guaranteed for all three operations. Keys kept in sorted order. No hash function required.
If you need to iterate keys in sorted order, or find the minimum/maximum, use a tree. If you just need fast lookups and do not care about order, use a hash table. Python gives you both: dict for hash-based lookup, sortedcontainers.SortedDict (or a manual approach) for sorted access.
Where Hash Tables Appear
Everywhere
- Python `dict` and `set`: Hash tables.
- JavaScript objects and `Map`: Hash tables.
- Database indexes (certain types): Hash indexes alongside B-tree indexes.
- Caching: Memcached and Redis are, at their core, very large distributed hash tables.
- Compilers: Symbol tables mapping variable names to their types and locations are hash tables.
The data structure is so fundamental that most languages build it into their syntax.
Conclusion
Hash tables are worth understanding deeply because they demonstrate a principle that appears throughout systems design: you can trade space and some worst-case guarantees for dramatically better average-case performance. The hash table does not guarantee O(1) — a bad hash function or adversarial inputs can degrade it to O(n) — but in practice, with a decent hash function and appropriate resizing, it is one of the fastest general-purpose data structures ever devised.
The next time you write {} in Python, you are standing on top of a surprisingly sophisticated piece of engineering.